LLVM 中的 SSA
如果看完本节以后还有感到迷惑的地方可以看下面这个视频
在阅读本节前我们默认你已经阅读过了 LLVM IR 快速上手 一节。
为什么要介绍这些内容?
在 LLVM IR 中,变量是以 SSA 形式存在的,为了生成正确的 LLVM IR 并实现我们的实验,对 SSA 的知识是必不可少的,LLVM IR 的代码有两种状态,分别是存取内存形式的 IR 以及带有 phi 指令的 SSA IR。因为 lab2 中已经涉及到了表达式相关的内容,所以本小节将对 SSA 进行简单的介绍,并指导大家设计合适的中间代码架构,以免实验到了后期因为设计问题出现大幅度重构。
在基础实验中,你只需要实现较简单的存取内存形式的 IR,而生成带有 phi 指令的 SSA IR 将被我们作为挑战实验发布。
SSA 介绍
静态单赋值(Static Single Assignment, SSA)是编译器中间表示中非常重要的一个概念,它是一种变量的命名约定。当程序中的每个变量都有且只有一个赋值语句时,称一个程序是 SSA 形式的。
在 LLVM IR 中,每个变量都在使用前都必须先定义,且每个变量只能被赋值一次(如果套用 C++ 的术语,就是说每个变量只能被初始化,不能被赋值),所以我们称 IR 是静态单赋值的。
举一个例子,如果想要返回 1 * 2 + 3 的值,我们下意识地就会像这样写。
%0 = mul i32 1, 2
%0 = add i32 %0, 3
ret i32 %0
很合理,不是吗?但这样写实际上是错的,因为变量 %0 被赋值了两次。我们需要修改为
%0 = mul i32 1, 2
%1 = add i32 %0, 3
ret i32 %1
SSA 的好处(拓展阅读)
对人类来说,第一种做法似乎更为直观,但是对于编译器来说,第二种做法带来的好处更多。
SSA 可以简化编译器的优化过程,譬如说,考虑这段代码:
d1: y := 1
一些无关代码
d2: y := 2
一些无关代码
d3: x := y
我们很容易可以看出第一次对 y 赋值是不必要的,在对 x 赋值时使用的 y 的值时第二次赋值的结果,但是编译器必须要经过一个定义可达性(Reaching definition)分析才能做出判断。编译器是怎么分析呢?首先我们先介绍几个概念(这些概念将会在我们课程的后半部分出现,我们在这里先 look ahead 一下,不完全理解也不影响实验的进行):
- 定义:对变量
x进行定义的意思是在某处会/可能给x进行赋值,比如上面的d1处就是一个对y的定义。 - kill:当一个变量有了新的定义后,旧有的定义就会被 kill,在上面的语句中
d2就 kill 了d1中对y的定义 - 定义到达某点:定义
p到达某点q的意思是存在一条路径,沿着这条路径行进,p在到达到点q之前不会被 kill。 - reaching definition:
a是b的 reaching definition 的意思是存在一条从a到达b的路径,沿着这条路径走可以自然得到a要赋值的变量的值,而不需要额外的信息。
按照上面的写法,d1 便不再是 d3 的 reaching definition, 因为 d2 使它不再可能被到达。
对我们来说,这件事情是一目了然的,但是如果控制流再复杂一点,对于编译器来说,它便无法确切知道 d3 的 reaching definition 是 d1 或者 d2 了,也不清楚 d1 和 d2 到底是谁 kill 了谁。但是,如果我们的代码是 SSA 形式的,那它就会长成这样。
d1: y1 := 1
一些无关代码
d2: y2 := 2
一些无关代码
d3: x := y2
编译器很容易就能够发现 x 是由 y2 赋值得到,而 y2 被赋值了 2,且 x 和 y2 都只能被赋值一次,显然得到 x 的值的路径就是唯一确定的,d2 就是 d3 的 reaching definition。而这样的信息,在编译器想要进行优化时会起到很大的作用。
SSA 带来的麻烦事
假设你想用 IR 写一个用循环实现的 factorial 函数:
int factorial(int val) {
int temp = 1;
for (int i = 2; i <= val; ++i)
temp *= i;
return temp;
}
按照 C 语言的思路,我们可能大概想这样写

然而我们会发现 %temp 和 %i 被多次赋值了,这并不合法。
怎么办?
plan a —— phi
phi 在基础实验中不要求生成,后面的挑战实验中的 mem2reg 的内容就是将 load/store 形式的 IR 转换为 phi 形式的 SSA。
在 clang -O1 选项下生成这个函数的 .ll 格式的文件,我们会发现生成的代码大概长这样:
define dso_local i32 @factorial(i32 %0) local_unnamed_addr #0 {
%2 = icmp slt i32 %0, 2
br i1 %2, label %3, label %5
3: ; preds = %5, %1
%4 = phi i32 [ 1, %1 ], [ %8, %5 ] ; 如果是从块 %1 来的,那么值就是 1,如果是从
ret i32 %4 ; 块 %5 来的,那么值就是 %8 的值
5: ; preds = %1, %5
%6 = phi i32 [ %9, %5 ], [ 2, %1 ]
%7 = phi i32 [ %8, %5 ], [ 1, %1 ]
%8 = mul nsw i32 %6, %7
%9 = add nuw i32 %6, 1
%10 = icmp eq i32 %6, %0
br i1 %10, label %3, label %5
}
phi 指令的语法是
<result> = phi <ty> [<val0>, <label0>], [<val1>, <label1>] ...
这个指令能够根据进入当前基本块之前执行的是哪一个基本块的代码来选择一个变量的值,有了 phi 以后我们的代码就变成了
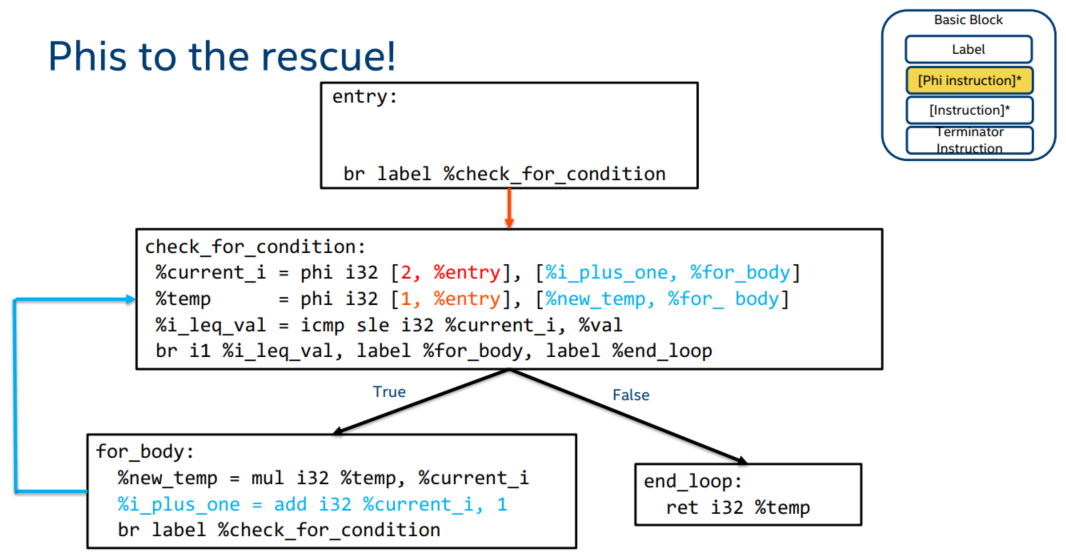
这样的话,每个变量就只被赋值一次,并且实现了循环递增的效果。
在这里你也可以发现:SSA 要求的是在静态,即仅从代码文本层面可以看出的单一赋值,而非运行时只会被赋值一次。
plan b —— alloca、load 与 store
前面铺垫了那么长时间,就是为了介绍 alloca,load 与store 三条指令以及他们的作用的。
在 -O0 选项下生成这个函数的 .ll 格式的文件,我们会发现生成的代码大概长这样
define dso_local i32 @factorial(i32 %0) #0 {
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 %0, i32* %2, align 4
store i32 1, i32* %3, align 4
store i32 2, i32* %4, align 4
br label %5
5:
%6 = load i32, i32* %4, align 4
%7 = load i32, i32* %2, align 4
%8 = icmp sle i32 %6, %7
br i1 %8, label %9, label %16
9:
%10 = load i32, i32* %4, align 4
%11 = load i32, i32* %3, align 4
%12 = mul nsw i32 %11, %10
store i32 %12, i32* %3, align 4
br label %13
13:
%14 = load i32, i32* %4, align 4
%15 = add nsw i32 %14, 1
store i32 %15, i32* %4, align 4
br label %5
16:
%17 = load i32, i32* %3, align 4
ret i32 %17
}
alloca 指令的作用是在当前执行的函数的栈帧上分配内存并返回一个指向这片内存的指针,当函数返回时内存会被自动释放(一般是改变栈指针)。
不难看出,这里的 .ll 文件所展示的 IR 中对一些局部变量存在多次 store 操作,但这些局部变量都是存放在内存中的,而非直接作为 LLVM IR 的一个虚拟寄存器被赋值。实际上,这是借助 LLVM IR 中只要求虚拟寄存器是 SSA 形式,而内存不要求是 SSA 形式的特点开了个后门来妥协,前端可以直接把局部变量分配到内存当中,放在内存里的变量不需要遵循 SSA 形式,可以经受多次定义。构造 SSA 的算法比较复杂,而且需要各种复杂的数据结构,这些因素导致在前端直接生成 SSA 形式的 IR 时非常麻烦。
基于上述的 trick,前端能够直接将变量按照栈的方式分配到内存当中,并且这个内存里的变量不需要遵循 SSA 形式,可以被多次定义,从而避免了构造 phi 指令产生的大量开销。
在 LLVM 中,所有的内存访问都需要显式地调用 load/store 指令。要说明的是,LLVM 中并没有给出“取地址”的操作符。以上面生成的代码中的 %3 为例,我们能在这些地方发现它
entry:
%3 = alloca i32, align 4
...
9:
...
%11 = load i32, i32* %3, align 4
...
store i32 %12, i32* %3, align 4
变量 %3 通过 alloca 声明,分配了一个 i32 大小的空间,这里 %3 的类型为 i32*,也就是说,%3 代表的是这段空间的地址,load 将 %3 所指向空间的内容读取出来,而 store 将新的值写入 %3 指向的空间。alloca 分配的栈变量可以进行多次存取,因此,通过 alloca、load 和 store,我们避免了 phi 指令的使用。
划重点,这种生成存取内存的 LLVM IR 的方法有四个特点:
- 每个可变变量都变为了栈上分配的空间(每个变量都变成了一条
alloca指令) - 每次对变量的读都变成了从内存空间中的一次读(每次读取一个变量都变成了通过
load对变量所在内存的读) - 每次对变量的写都变成了对内存的一次写(每次更新一个变量的值都变成了通过
store对变量所在内存的写) - 获取变量的地址等价于获取内存的地址
不难发现,这种方法虽然避免了 phi 的出现,但是每次变量的存取都变成了访问内存,这会导致严重的性能问题。所幸,正如我们之前所说的,LLVM 提供了一个叫做 mem2reg 的解决方案,它能够把 alloca 指令分配的内存变量转化为 SSA 形式的 LLVM IR 虚拟寄存器变量,并且在合适的地方插入 phi 指令。
LLVM 官方非常支持使用上述 alloca + mem2reg 技术,clang 默认不开优化生成的就是存取内存形式的 IR。alloca 技术可以把前端从繁琐的 SSA 构造工作中解脱出来,而 mem2reg 则可以极其快速地生成 SSA 形式。这两者的结合大大提高了编译的效率。
在基础实验中,你只需要实现较简单的存取内存形式的 IR,而生成带有 phi 指令的 SSA IR 将被我们作为挑战实验发布。